4.监控Kubernetes Pods
监控Pod
设置采集匹配规则
上面的 apiserver 实际上就是一种特殊的 Endpoints,现在我们同样来配置一个任务用来专门发现普通类型的 Endpoint,其实就是 Service 关联的 Pod 列表:
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
# 当prometheus.io/scrape: "true" 可以让prometheus自动发现
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__ #替换源标签的值。
regex: (https?) #表示一个匹配 https 或 http 的组。
#括号 () 用于定义一个组,https? 表示匹配 https,
#后面的 ? 表示匹配零次或一次前面的字符,因此 https? 可以匹配 https 或 http。
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
#prometheus.io/path: metrics 匹配接口地址
- source_labels:
[__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+) # RE2 正则规则,+是一次多多次,?是0次或1次,其中?:表示非匹配组(意思就是不获取匹配结果)
replacement: $1:$2 # 表示将匹配到的地址和端口号使用冒号连接起来,作为 __address__ 标签的新值。
# ([^:]+) 匹配地址部分,即不包含冒号的一串字符。
# (?::\d+)? 匹配冒号后跟着端口号的部分,可选匹配,即匹配冒号后跟着一个或多个数字的模式,如果存在则表示端口号。
# ; 分隔地址和端口号的部分。
# (\d+) 匹配端口号,即一个或多个数字。
完整配置
- job_name: "kubernetes-endpoints"
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels:
[__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+) # RE2 正则规则,+是一次多多次,?是0次或1次,其中?:表示非匹配组(意思就是不获取匹配结果)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
设置pod采集声明
注意我们这里在 relabel_configs 区域做了大量的配置,特别是第一个保留 __meta_kubernetes_service_annotation_prometheus_io_scrape 为 true 的才保留下来,这就是说要想自动发现集群中的 Endpoint,就需要我们在 Service 的 annotation 区域添加 prometheus.io/scrape=true 的声明,现在我们先将上面的配置更新,查看下效果:
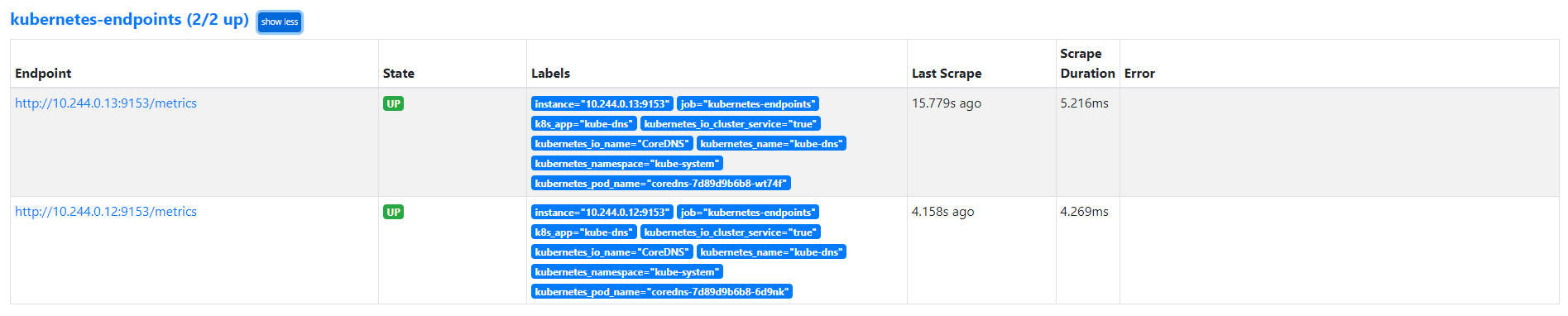
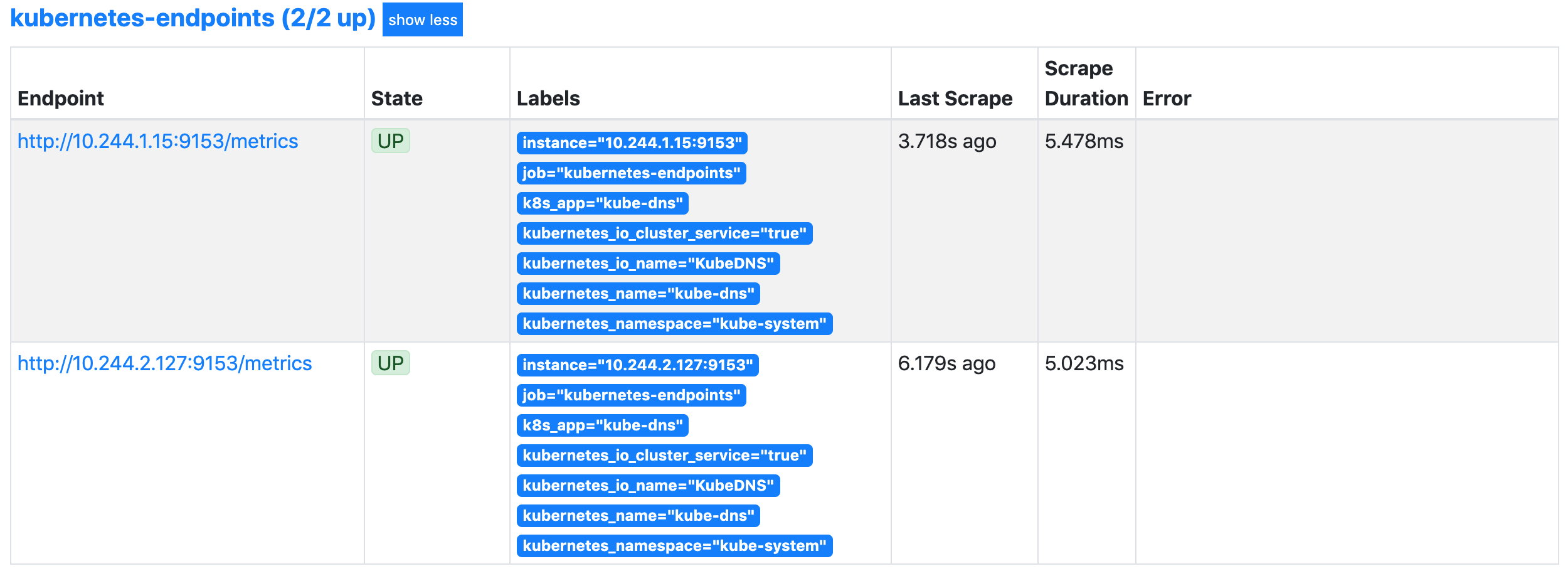
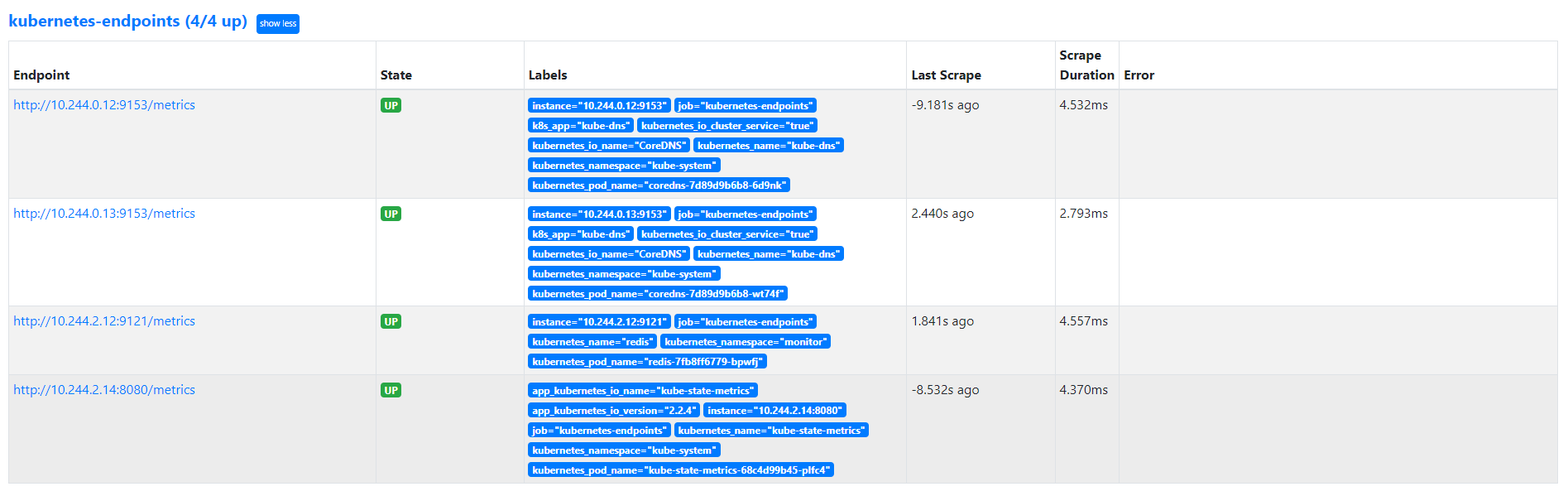
我们可以看到 kubernetes-endpoints 这一个任务下面只发现了两个服务,这是因为我们在 relabel_configs 中过滤了 annotation 有 prometheus.io/scrape=true 的 Service,而现在我们系统中只有这样一个 kube-dns 服务符合要求,该 Service 下面有两个实例,所以出现了两个实例:
kubectl get svc kube-dns -n kube-system -o yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9153" # metrics 接口的端口
prometheus.io/scrape: "true" # 这个注解可以让prometheus自动发现
creationTimestamp: "2023-03-12T03:16:32Z"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: CoreDNS
name: kube-dns
namespace: kube-system
......
现在我们在之前创建的 redis 这个 Service 中添加上 prometheus.io/scrape=true 这个 annotation:(prome-redis.yaml)
kind: Service
apiVersion: v1
metadata:
name: redis
namespace: monitor
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
由于 redis 服务的 metrics 接口在 9121 这个 redis-exporter 服务上面,所以我们还需要添加一个 prometheus.io/port=9121 这样的 annotations,然后更新这个 Service:
$ kubectl apply -f prometheus-redis.yaml
deployment.apps/redis unchanged
service/redis configured
更新完成后,去 Prometheus 查看 Targets 路径,可以看到 redis 服务自动出现在了 kubernetes-endpoints 这个任务下面:
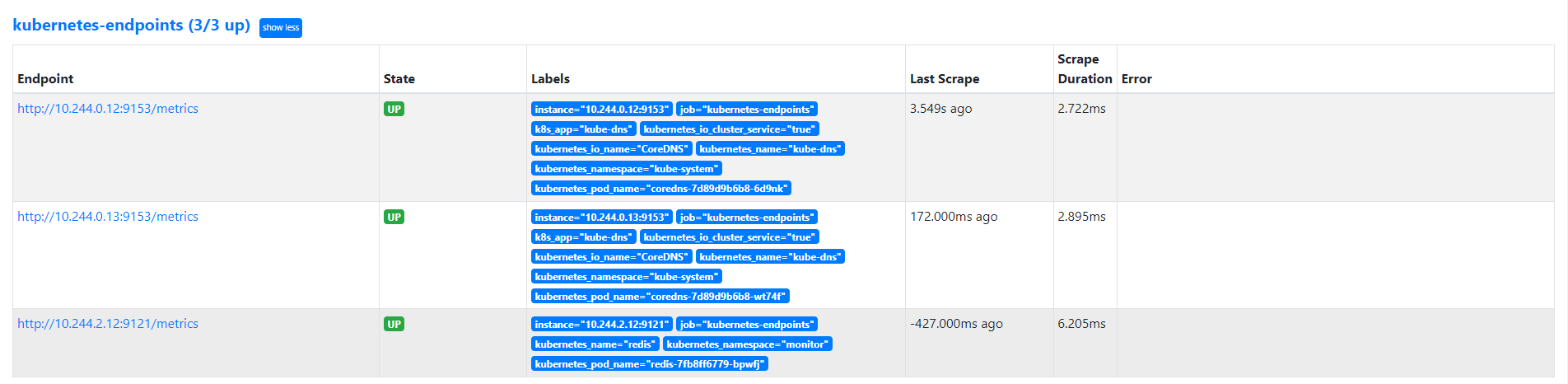
这样以后我们有了新的服务,服务本身提供了 /metrics 接口,我们就完全不需要用静态的方式去配置了,到这里我们就可以将之前配置的 redis 的静态配置去掉了。
把之前的CoreDNS 更改为服务发现模式
- job_name: 'coredns-sd'
kubernetes_sd_configs:
- role: endpoints
#scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-dns;metrics
在 Service Discovery中查看过滤条件__meta_kubernetes_endpoint_port_name的值为 metrics

添加以后查看数据

kube-state-metrics
上面我们配置了自动发现 Endpoints 的监控,但是这些监控数据都是应用内部的监控,需要应用本身提供一个 /metrics 接口,或者对应的 exporter 来暴露对应的指标数据,但是在 Kubernetes 集群上 Pod、DaemonSet、Deployment、Job、CronJob 等各种资源对象的状态也需要监控,这也反映了使用这些资源部署的应用的状态。比如:
- 我调度了多少个副本?现在可用的有几个?
- 多少个 Pod 是 running/stopped/terminated 状态?
- Pod 重启了多少次?
- 我有多少 job 在运行中等等
通过查看前面从集群中拉取的指标(这些指标主要来自 apiserver 和 kubelet 中集成的 cAdvisor),并没有具体的各种资源对象的状态指标。对于 Prometheus 来说,当然是需要引入新的 exporter 来暴露这些指标,Kubernetes 提供了一个kube-state-metrics 就是我们需要的。
与 metric-server 的对比
- 功能:
- Kube-state-metrics 是一个监控指标导出器,它从 Kubernetes API Server 获取集群的当前状态信息,并将这些信息转换为 Prometheus 可以理解的指标格式。这些指标包括 Pod、Node、Deployment、Service 等对象的状态信息,以及这些对象的数量、状态、标签等。
- Metric Server 是一个 Kubernetes 组件,用于收集和存储集群资源的使用指标。它从 Kubernetes API Server 获取资源使用情况的度量值,如 CPU 和内存使用量,并将这些度量值暴露给 kubelet,以便其他组件(如 HPA)使用。
- 指标内容:
- Kube-state-metrics 提供了丰富的状态信息,如 Pod、Node、Namespace、Deployment、StatefulSet 等对象的状态指标。
- Metric Server 主要提供了资源的使用指标,如 CPU 和内存的使用量、资源请求和限制等。
- 使用场景:
- Kube-state-metrics 适用于监控 Kubernetes 集群中的状态信息,以及各种对象的数量和标签等。它通常用于创建自定义监控面板和警报规则。
- Metric Server 主要用于水平自动伸缩(HPA)等场景,它提供了 Kubernetes 集群中资源的实时使用情况,以便根据负载情况进行自动伸缩。
Kube-state-metrics 主要提供 Kubernetes 集群中的状态信息指标,而 Metric Server 则提供资源的实��时使用指标。
安装 kube-state-metrics
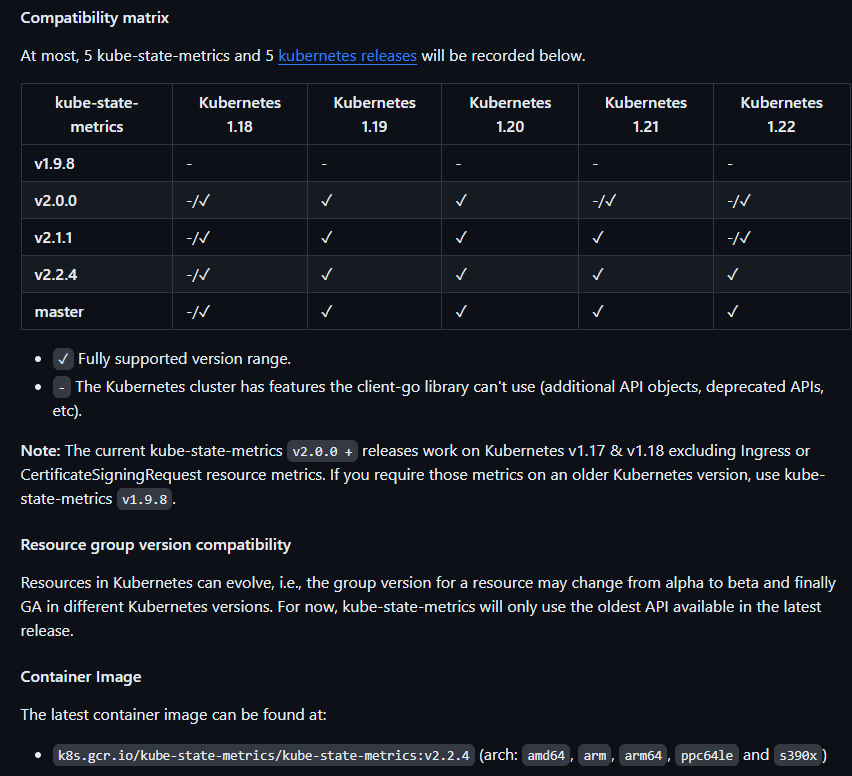
kube-state-metrics 已经给出了在 Kubernetes 部署的 manifest 定义文件,我们直接将代码 Clone 到集群中(能用 kubectl 工具操作就行),不过需要注意兼容的版本:
git clone https://github.com/kubernetes/kube-state-metrics.git
cd kube-state-metrics/examples/standard
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.2.4
默认的镜像为 gcr 的,这里我们可以将 deployment.yaml 下面的镜像替换成 registry.cn-hangzhou.aliyuncs.com/xxk8s/kube-state-metrics
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.2.4
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.2.4
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/xxk8s/kube-state-metrics:v2.2.4
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
给 kube-state-metrics 的 Service 配置上对应的 annotations 来自动被发现,然后直接创建即可:
$ cat service.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.2.4
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080" # 8081是kube-state-metrics应用本身指标的端口
name: kube-state-metrics
namespace: kube-system
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics
➜ cat service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.0.0-rc.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080" # 8081是kube-state-metrics应用本身指标的端口
name: kube-state-metrics
namespace: kube-system
apiVersion: apps/v1
......
kubectl apply -f .
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
service/kube-state-metrics created
$ kubectl get pod -n kube-system | grep kube-state-metrics
kube-state-metrics-68c4d99b45-plfc4 1/1 Running 0 57s
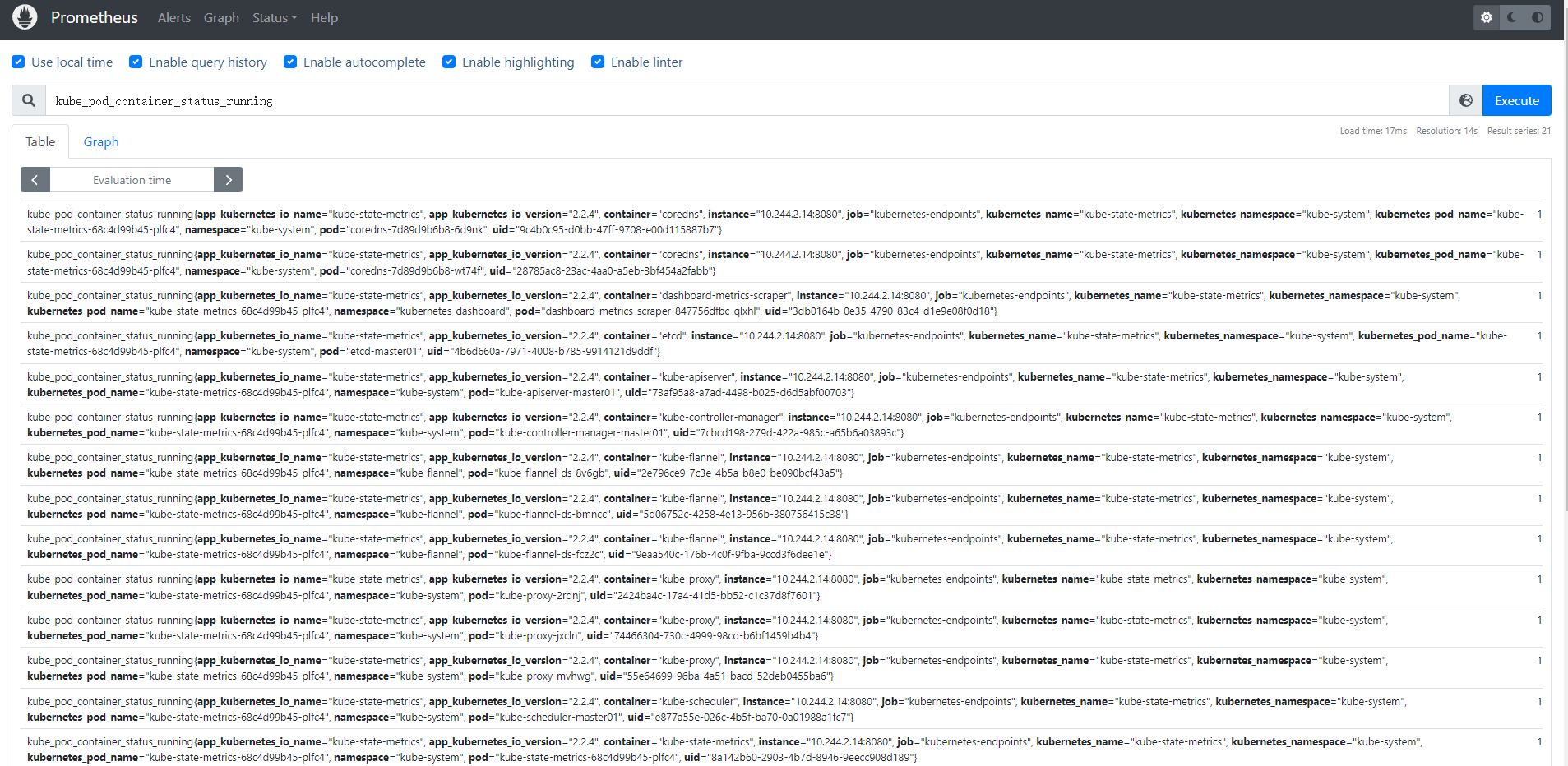
部署完成后正常就可以被 Prometheus 采集到指标了:
水平缩放(分片)
kube-state-metrics 已经内置实现了一些自动分片功能,可以通过--shard 和 --total-shards 参数进行配置。现在还有一个实验性功能,如果将 kube-state-metrics 部署在 StatefulSet 中,它可以自动发现其命名位置,以便自动配置分片,这是一项实验性功能,可能以后会被移除。
要启用自动分片,必须运行一个 kube-state-metrics 的 StatefulSet,并且必须通过 --pod 和 --pod-namespace 标志将 pod 名称和名称空间传递给 kube-state-metrics 进程。可以参考 /examples/autosharding 目录下面的示例清单文件进行说明。
采集数据
使用 kube-state-metrics 的一些典型场景
- 存在执行失败的
Job: kube_job_status_failed - 集群节点状态错误:
kube_node_status_condition{condition="Ready", status!="true"}==1 - 集群中存在启动失败的 Pod:
kube_pod_status_phase{phase=~"Failed|Unknown"}==1 - 最近 30 分钟内有 Pod 容器重启:
changes(kube_pod_container_status_restarts_total[30m])>0
metric_relabel_configs
现在有一个问题是前面我们做 endpoints 类型的服务发现的时候做了一次 labelmap,将 namespace 和 pod 标签映射到了指标中,但是由于 kube-state-metrics 暴露的指标中本身就包含 namespace 和 pod 标签,这就会产生冲突,这种情况会将映射的标签变成 exported_namespace 和 exported_pod,这变会对指标的查询产生影响,如下所示:
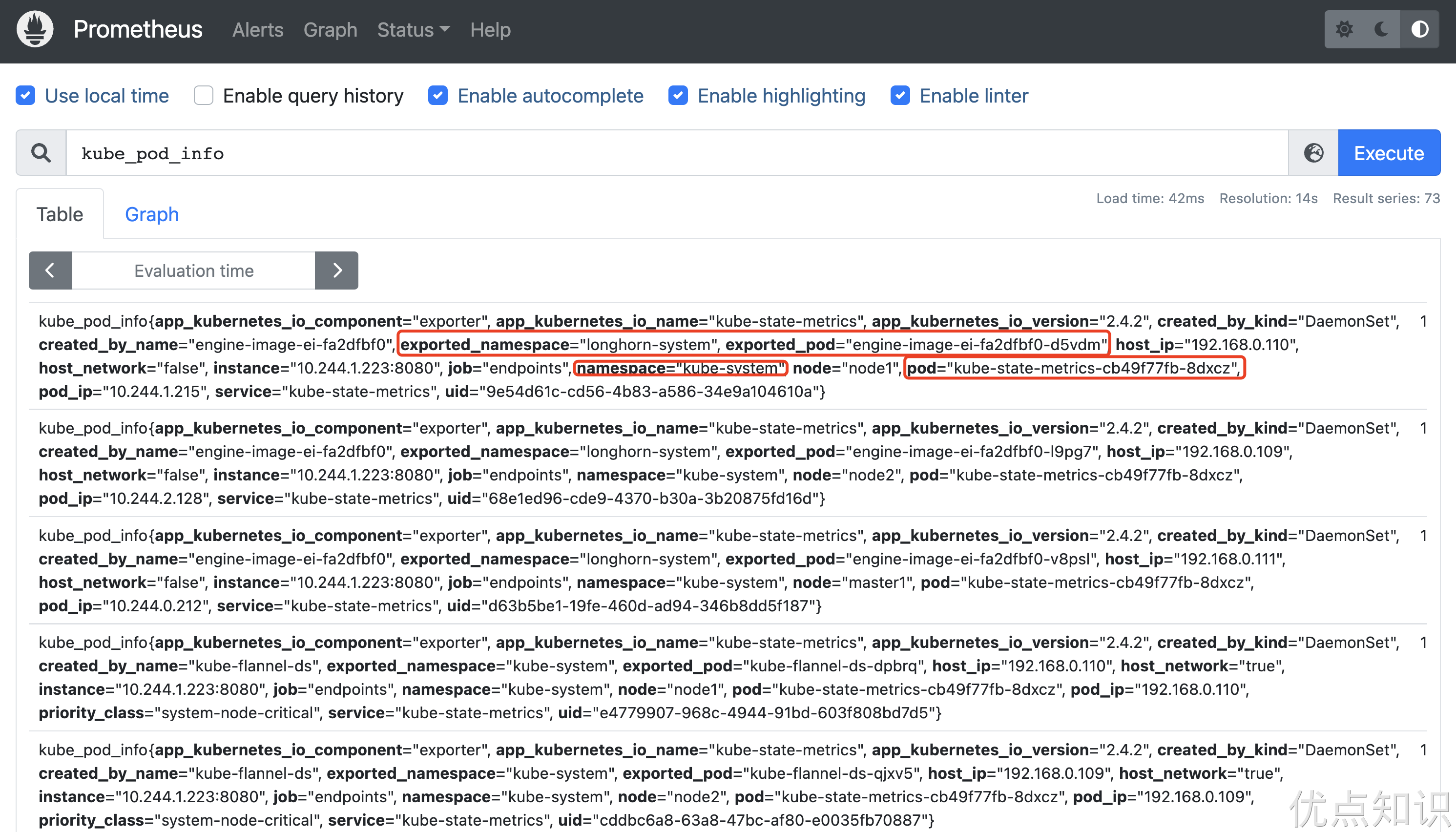
这个情况下我们可以使用 metric_relabel_configs 这 Prometheus 保存数据前的最后一步重新编辑标签,metric_relabel_configs 模块和 relabel_configs 模块很相似,metric_relabel_configs 一个很常用的用途就是可以将监控不需要的数据,直接丢掉,不在 Prometheus 中保存。比如我们这里可以重新配置 endpoints 类型的指标发现配置:
- job_name: "endpoints"
kubernetes_sd_configs:
- role: endpoints
metric_relabel_configs:
- source_labels: [__name__, exported_pod]
regex: kube_pod_info;(.+)
target_label: pod
- source_labels: [__name__, exported_namespace]
regex: kube_pod_info;(.+)
target_label: namespace
- source_labels: [__name__, exported_node]
regex: kube_pod_info;(.+)
target_label: node
- source_labels: [__name__, exported_service]
regex: kube_pod_info;(.+)
target_label: service
relabel_configs:
# ......
新版本kube-state-metrics 暴露的指标不包含 namespace 和 pod 标签了
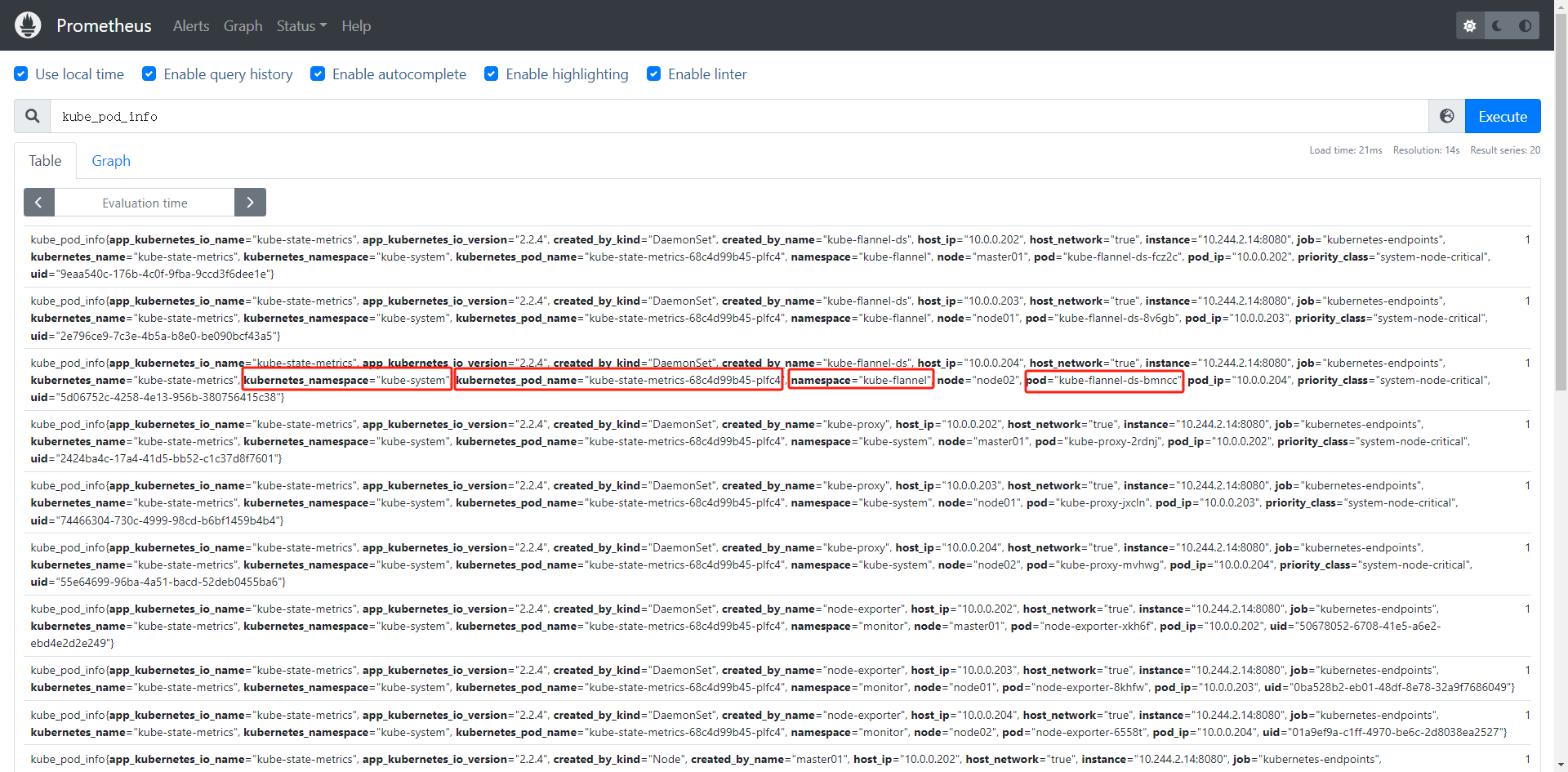
metric_relabel_configs 与 relabel_configs 的区别
relabel_configs 和 metric_relabel_configs 是 Prometheus 配置中的两个重要部分,它们在监控系统中起着不同的作用。relabel_configs 用于在 Prometheus 从目标获取指标之前或抓取过程中对目标进行筛选和重标记,而 metric_relabel_configs 则用于在 Prometheus 抓取到指标后对指标进行筛选和重标记。
relabel_configs 典型用例:
选择要抓取的目标,例如根据标签选择特定类型的机器。
重命名或删除目标标签,以符合你的监控需求。
metric_relabel_configs 典型用例:
删除昂贵的指标,以减少存储和处理成本。
对来自抓取目标本身的标签进行操作,例如根据 /metrics 页面上的标签进行过滤或操作。
譬如下面的 relabel_configs drop 动作:
relabel_configs:
- source_labels: [__meta_xxx_label_xxx]
regex: Example.*
action: drop
那么将不会收集这个指标,而 metric_relabel_configs 使用的时候指标已经采集过了:
metric_relabel_configs:
- source_labels: [__name__]
regex: "(container_tasks_state|container_memory_failures_total)"
action: drop
所以 metric_relabel_configs 相对来说,更加昂贵,因为指标已经采集了。
关于 kube-state-metrics 的更多用法可以查看官方 GitHub 仓库:https://github.com/kubernetes/kube-state-metrics